
Last year, I regularly travelled to speak at conferences or meet customers to discuss software security. During such times, I spoke with many software and security leaders, each opening up a floodgate of conversation for a real cathartic release. Everything seemed hard: tools not working as expected, teams not adopting them, people not listening, and issues with legacy engineering. But what is the most common frustration by far? The answer—dependencies.
Dependencies are a universal concern. Nobody felt that the issue was managed well, whether it was keeping things reasonably current, responding to critical bugs, or keeping things operational. Nor should they. Our approaches to the issue haven’t changed much since 2018, but AI should be a wake-up call to revisit the topic. In this article, I wanted to cover what that innovation looks like.
>>> import dep-mgmt-kb
Before we go too deep, let’s cover the basics. Developers can write code or use a dependency to achieve their goals. Dependencies are readily available, maintained, and generally considered more secure. Most importantly, they improve productivity. Reinventing the wheel gets old fast.
In the past, dependencies were bundled directly with software projects, usually in the form of jar or DLL files. Today, we use package repositories and package managers to simplify this task. Some examples include npm, PyPi, Crates, NuGet, RubyGems, Maven, etc. Many early commercial security solutions have built their features directly into these same package managers today.
As dependency use grew, malicious actors began to target the ecosystem. Other problems around reproducibility and redundancy also began to bubble up. Tools and processes were built or introduced to help mitigate these challenges.
Some of those challenges include:
- You didn’t know what code you were importing. Without visibility, teams couldn’t adequately respond to security threats. Package manifest files and software bill of materials adoption help solve this.
- We don’t know whether a library is malicious. Binary repositories were used to block ‘unreviewed’ packages, and threat intelligence feeds often provided data to help security teams identify suspicious activity.
- Not knowing whether a library is vulnerable. Software composition analysis tools helped to map known vulnerabilities to packages, creating a prioritisation methodology for patch cycles.
- Falling behind on patching. Stale libraries often became a security challenge and operational risk. The result was days of annoying troubleshooting issues, which was not helpful when responding to a new security issue. Package managers and SCMs helped remind people to patch libraries as they became stale.
- Not having a patch available. Some dependencies are end-of-life or reliant on downstream components to patch before they can be fixed. Mitigations like WAFs were preferable to forking and fixing a library.
Many other threat vectors include dependency confusion, typosquatting, namespace hijacking, and others. The purpose of this post isn’t to cover all supply chain issues, as SLSA addresses these well.
Instead, we should recognise that dependency management is an enormous field with many parts to address and that we should be proud of the innovations and contributions of companies like Sonatype, Snyk, Blackduck, Github, and more.
Automated Raising of Pull-Requests
Around 2015, existing software security players were focused on language coverage and vulnerability identification. Products were designed for security auditors, not for a DevOps world. Shifting left is hard when tools require bespoke configurations, need processing time to give meaningful feedback, and otherwise couldn’t keep up with the Cambrian explosion of tech stack disparity as Java / .NET fell out of favour. Wrappers and other integration code helped, but building and maintaining skunkworks around a tool became a maintenance nightmare.
I still know that AppSec teams are maintaining shell scripts on ancient Jenkins servers today.
So, a product designed and marketed towards software engineers that addressed a security challenge and fell within standard engineering practices was well received. That was Snyk, and Snyk is an enormously successful company today. Automated dependency upgrades with Snyk is one of the core features of Snyk and other developer-first AppSec tools, automatically raising pull-requests to fix security bugs. Initially, this functionality was targeted at dependency management. Checking code out, incrementing the version of a library in the package manifest file, committing the changes to a new branch, and raising a pull-request was reasonably straightforward. Many products today, significantly when augmented with AI, go further and suggest code fixes when they raise pull-requests.
Many AppSec practitioners come from penetration testing or governance backgrounds, so ‘automatic patching’ seems like a great idea. Developers love to merge these automated pull-requests, right?
Requesting to Pull out my hair
On paper, it’s great. In practice.. eh. The first challenge is noise. All software composition analysis products report vulnerabilities, including those directly or transitively included, through the dependency chain. I’ll use Wiz Code as our example, released only a few months ago.
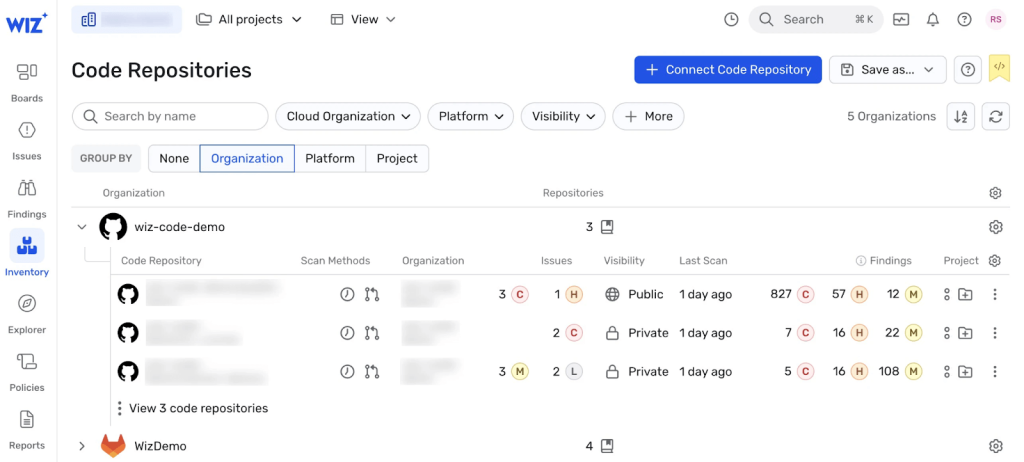
“Figure 1 shows a Wiz Code scan of multiple repositories with their respective vulnerability scan findings. For example, the first repository has 827 critical, 57 high, and 12 medium vulnerabilities. With this information in hand, it becomes easier for engineers to start looking for potential fixes and respond to issues earlier when they’re easier and cheaper to fix.”
Wiz is a market leader in cloud security. However, I don’t think they understand software security yet. It’s early days in their product journey. Still, this screen effectively represents the worst-case scenario for a developer.
- Nobody wants 1 blinking red light, let alone 827 of them. The developers here are clearly in dependency hell. If they try to patch one component, it breaks something elsewhere. We know from broken window theory that if nobody has fixed it yet, nobody will. It’ll take a breach before people consider vendoring necessary code, ripping out problematic libraries, or starting to tackle this.
- Okay, Orpheus, where do you start? When presented with so many options, analysis paralysis sets in. Turning all the Christmas lights on at once will overwhelm the kids. We don’t want developers to give up on the problem before they even start.
- Lastly, I disagree with their view that looking for fixes and responding to issues is easier. Developers are paid to build and maintain software. It’s demeaning to the profession to think that they aren’t planning how to patch dependencies. Patching is a source of constant stress for most, and most build tools constantly remind them to patch. We want developers to build software, not stressing about package updates.
Back to SCA, the automated raising of pull-requests is noisy. Regardless of the product, after a few days you’ll probably encounter something like this.
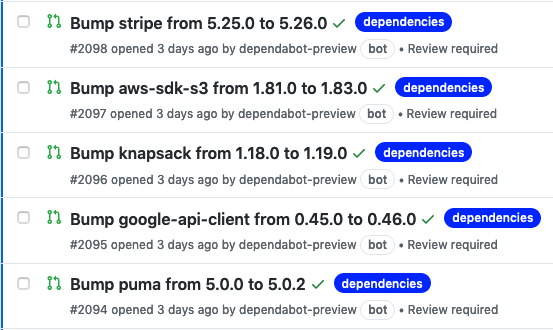
Which seems fine? Well, here are a few Reddit commentators on it.



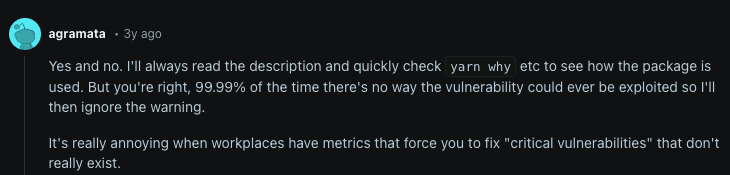
It makes me think that doing nothing is the desired path. If so, what value is there in automatically raising pull-requests if they are ignored and never merged?
Secondly, breaking changes. It is a desired property for our software to be buildable, reproducible, and to function as intended. The most straightforward approach is to pin a specific software version and its underlying dependency chain. At some point, new features may be introduced, bugs may be fixed, security issues may arise, or libraries may become deprecated or obsolete. Any of these may lead to a requirement to patch or seek an alternative library. This approach may introduce breaking changes that need some level of critical thinking to resolve the issue.
The automatic raising of pull-requests is problematic here too. Tools that aim for granular upgrades are safer, but become a chore to work with at scale. Bundling upgrades is more efficient, but frequently results in broken builds, rollbacks, and troubleshooting. Having great functional tests, and broad test coverage helps, but I’ve rarely seen that in practice.
Finally, there’s the productivity impact around vulnerability management and dependencies. Dependency upgrades are prioritised unnecessarily. Security tools overwhelmingly flag code that could be exploited but often have minimal or zero actual impact. Minor version bumps that only include refactoring changes are included in SLA. Raising an automated pull-request requires a developer to understand if a patch will cause problems before they merge. For smaller projects, it’s not a big deal. At scale, especially with mono-repo architectures, it can monopolise engineering efforts to stay current. That’s unproductive and costly.
We want to be targeted and effective with our vulnerability management, keep our build processes safe and stable, and reduce productivity bottlenecks and disruptions. Time to cover the opportunity we have to do better.
Silencing the Noise
AppSec products are noisy. That’s always been an intentional choice by product vendors. Missing a vulnerability had a greater consequence than finding a false positive. Today, all products are great at finding bugs. However, they struggle with accuracy and relevance, which are equally important for businesses seeking cost-efficiency and effectiveness. The innovation opportunity here is around verification and contextualising risk.
Many dependency management products rely on package manifest files that specify top-level dependencies. These are mapped against public and private vulnerability databases, quickly identifying packages with known vulnerabilities. However, deeper analysis is more challenging with this approach. Innovative companies are asking the question, “How do we verify a vulnerable function is callable?” The answer is using static analysis to determine function reachability.
Companies like Endor Labs believe that demonstrating exploitability isn’t necessary. Full AST-based taint analysis is computationally prohibitive and hard to maintain. Old-school static analysis tools completely failed to support new technologies or version upgrades. Instead of performing data-flow analysis, Endor precomputes a call graph for each vulnerable dependency. SCA results are verified by a static check to see whether your custom code overlaps with the graph. Understanding reachability with Endor Labs keeps scans fast, but critically, it significantly reduces the quantity of issues to a manageable level for developers.
An alternative approach to reducing noise? Context. ASPM products like Aikido Security innovate here by considering context, performing deduplication, and correlating across scanning engines. Enhancing security posture with Aikido Security is a great example of this, grouping findings by remediation paths or root causes, and intelligently hiding issues without remediation paths. They make judgments about the purpose of code, hiding test or developer dependencies. If a finding is found across different engines, it’s more accurate and given a heavier prioritisation weight.
The aim is to contextualise what matters and otherwise hide irrelevant bugs.
Safe Patching
Anyone who has had to fix software dependencies knows the impact of letting your packages go stale. Reporting an ever-increasing number of security vulnerabilities won’t improve your security posture. It just creates stress and anxiety, especially if you know you are stuck in dependency hell.
To get our libraries current, we need to give developers an explicit pathway rather than let them suffer hours, days, or potentially weeks of troubleshooting. Companies like Infield understand this and break a large work program into discrete incremental steps. Others like Myrror identify components with breaking changes and give developers feedback that they’ll need to make code changes.
It’s still early days, but I expect that AI will reshape many aspects of the patching process. One approach I’ve seen includes generating new test suites for a library, bumping the version, and then running those tests again to validate that the security issue was fixed and the functionality is intact. Others try to score a patch risk rating and let developers make educated decisions about merging the automated pull-requests. Another is applying virtual patches to mitigate the security bug until the broader patch is applied, like Seal Security. Applying virtual patches with Seal Security helps reduce the urgency of immediate upgrades when code changes are risky or infeasible.
The innovation? We want to distinguish between safe and unsafe patches and guide us when breaking changes are introduced.
Improving Productivity
The last aspect concerns improving the productivity of our software engineers. Existing products try to do this in clunky ways by specifying dependencies to ignore, limiting the number of pull-requests raised, or only bumping minor versions. However, these solutions still create bottlenecks as humans need to review each pull request.
Leaving a bottleneck untreated will always cost more than resolving it. Innovations here are around optimising human effort by removing chores or building a better experience. For example, most automated pull-requests traditionally provide shallow commentary. They link to a CVE but have no other information about the component, its impact on the build process, or version differences that engineers should pay attention to. Today, companies like Nullify are giving engineers detailed context around the pull request, reducing the investigation time needed to determine if it should be merged.
There is a lot of commentary around making decisions autonomously about minor versions or staleness, but I figure that most organisations don’t have the level of test coverage necessary to explore this path deeply yet. But with the pace of AI, it won’t be far off, and then we need even less human involvement.
Lastly, batching and patching. It’s simple, but by alerting only when necessary and maintaining a scheduled patching cadence, developers can focus on feature delivery, not firefighting, in response to new software versions being made available.
Pulling it together
This article isn’t meant to attack existing players. At this point, Dependabot alone has raised billions of pull-requests and perhaps single-handedly raised open-source security globally. That’s pretty good for a product that is available for free. Snyk’s is in a similar boat, as they have one of the best vulnerability databases available and continue to push for developer experience across all of their workflows.
Before going out and buying these new tools, it’s important to remember that people get cut on the bleeding edge. I’ve outlined that these new approaches to dependency management are still in their infancy. The level of maturity that we would expect of enterprise products isn’t there yet. So don’t throw the SCA out with the bathwater yet. Ask yourself this:
- Do they support the tremendous backlog of enterprise languages and frameworks and older versions of those? It would be nice if everyone used modern JavaScript, but I still encounter Perl, Delphi, and COBOL every now and then. Supporting the 20-something years of the Java ecosystem, which underpins most modern banking, is in and of itself a big challenge.
- Do they integrate with typical enterprise products? To list a few, Corporate Identity, Office Collaboration, Dev Tools, Security (IAM, EDR, Backups, DLP, SIEM, GRC, etc), ETL/Data, ITOM, Telephony and Comms, Project Management, Support, and plenty more… Often startups focus on a specific audience, and build these features as they mature into the enterprise space.
- Do they have a local presence? Can they reasonably support you? Many companies rely on channel or integration partners who are often just as knowledgeable as your internal developers are with cutting-edge AppSec tools. Waiting until they expand into your region may make sense.
- How long have they been in business? It’s an unfair but reasonable question. Building your processes around an unsustainable business could mean a complete rework in the future when the company shrinks, gets acquired, or closes down. Business is hard.
Ultimately, we will see some changes over the next few years. Whether large players shift their focus to products again and adopt some of these innovations or get challenged by the new businesses remains to be seen.
The future of dependency management… Looks Good To Me!





